Datadreven beslutningsstøtte – transparent og forklarlig dataanalyse til alle

Der indsamles i disse år enorme mængder data – ”Big Data” – i virksomheder inden for de fleste brancher, lige fra konventionelt manuelle erhverv i f.eks. plejesektoren og byggebranchen til højteknologiske brancher så som forsvarsindustrien og produktionssektoren. Data indsamles ofte ud fra devisen om, at der er viden og værdi i data – hvilket i høj grad er sandt – og dataindsamling sker ofte i regi af Big Data projekter. Men for at drage nytte af de indsamlede data, er det nødvendigt at analysere data med sofistikeret Machine Learning (ML) og visualiseringsværktøjer, således at virksomheder kan udnytte data til at træffe bedre beslutninger. Dette skaber en række udfordringer, som vi vil adressere i denne aktivitetsplan.Udfordringerne består i et behov for transparens af ML og datadrevne analysemodeller samt et behov for at forklare deres resultater, især når de bliver uigennemskuelige for både den almene bruger og ekspertbrugeren. Dette er særligt nødvendigt, når data og beslutninger vedrører personer. Her kræver GDPR nemlig, at beslutninger skal kunne forklares over for de parter, beslutningerne berører.
Øget transparens og forbedret forklaringsevne er derfor påkrævet for at kunne styrke tilliden til datadrevne beslutningsstøtteværktøjer og for at gøre ML og store datamængder mere tilgængelige for et bredere udvalg af brugere og derved udvide anvendelsesområdet af datadrevne modeller. Forøgelse af transparens og forklaringsevne i beslutningsstøtteværktøjer kan bl.a. indebære at visualisere data i værktøjerne samt at forklare, hvilke dele af dataene fører til et vist resultat.
Transparens og evne til at forklare datadreven beslutningsstøtte er en del af ”explainable AI”, altså forklarlig kunstlig intelligens. Dette kan brydes ned i de følgende problemstillinger inspireret af Casimir Wierzynski, Senior Director hos Intel, der beskriver udfordringer for ML (link):
P1. Evne til at forklare resultater: Kan vi bygge modellen, så som den kan forklare resultater til enhver person på en forståelig måde? Dermed vil datadreven beslutningsstøtte være mere tilgængelig, og dette kunne også kræves af GDPR.
P2. Evne til at forklare grundlæggende mekanismer: Kan vi forklare grundlæggende mekanismer af problemet ved hjælp af en ML-model, dvs. ikke kun give et resultat men også forklare, hvilke dele af data har påvirket resultatet mest? Dermed vil man kunne forstå både problemet og løsningen bedre.
P3. Transparens af modellen: Kan vi skabe indblik i modellens processer ved hjælp af værktøjer? Dette vil gøre det nemmere for enhver person at forstå ML-modellens virkninger og dermed skabe en lettere adgang til datadreven beslutningsstøtte.
P4. Bias og fairness: Kan vi identificere bias i eksisterende systemer? Hvilken indflydelse har bias på datadreven beslutningsstøtte? Kan vi verificere, at beslutninger er truffet på retfærdig vis, dvs. undgå at en gruppe diskrimineres i forhold til anden, eksempelvis sørge for, at alle har samme mulighed for at få et lån. Dette er primært også et samfundsmæssigt behov, da vi garanterer, at beslutninger er retfærdige over for alle, der berøres af dette, og dermed kan tilliden til ML-systemer øges.
For at adressere P1-4 vil vi udvikle nye algoritme- og visualiseringsværktøjer der gøre det muligt for domæneeksperter at udforske og kontrollere de automatiske analysemetoders resultater og virkninger uden teknisk indsigt i ML-teknologien.
Derudover vil vi udvikle ydelser, der hjælper virksomheder med at identificere hvilke state-of-the-art ML-modeller, der sammen med de udviklede værktøjer kan løse deres udfordringer. Det vil øge antallet af mulige anvendelsesområder og effektiviteten af datadrevne modeller i praksis.
For at øge fairness i datadrevne modeller (P4) vil vi udvikle en rådgivningsydelse til at informere om fairness i data og datadrevne modeller. Desuden vil vi opbygge en vidensbase om årsager og virkninger af bias i datadrevne modeller. Disse kompetencer kan bruges til at yde konsultation til virksomheder om fairness af deres modeller og give retningslinjer for god praksis for brug af datadreven beslutningsstøtte.
Teknologier og værktøj til udnyttelse af Big Data
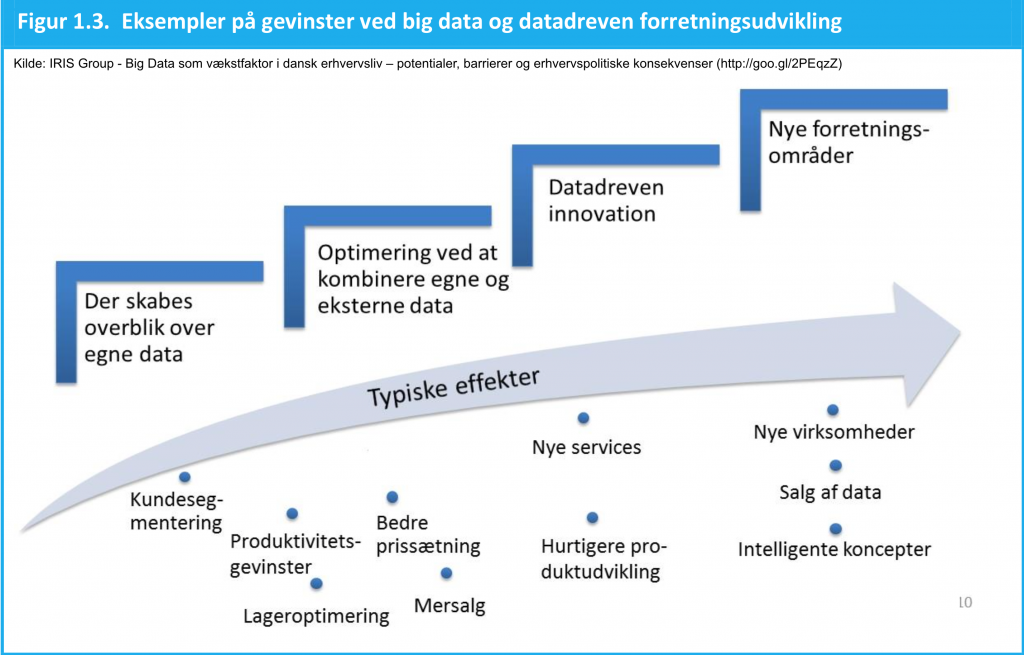
Der er stort uudnyttet værdipotentiale for danske virksomheder i udnyttelsen af Big Data. En række undersøgelser, bl.a. fra Erhvervsstyrelsen, har identificeret et hul i markedet og specifikke barrierer for danske virksomheder i at udnytte potentialet. Desuden mangler virksomhederne adgang til kompetencer inden for teknologier og forretningsprocesser, der addresserer Big Data for at overkomme deres barrierer.I dette projekt gennemføres en række aktiviteter og resulterende ydelser, som direkte adresserer en række af de identificerede barrierer og hermed forbedrer virksomhedernes mulighed for at få andel i værdipotentialet i Big Data. Den primære målgruppe er virksomheder inden for: IKT, energi og forsyning og e-handel.
